Hire engineers who
actually ship.
Agentic assessments that measure how candidates work with AI, not how well they memorized LeetCode in 2019.
OA mode is in active development. Join early access and we’ll set up a pilot when it’s ready.
Stop hiring for 2019 skills.
Your best engineers ship with AI in the loop. Your current OA pretends that doesn't happen, and you lose the top 20% of candidates the moment they realize it.
AI-“cheating” framing
Banning assistants and simulating 2015 doesn't make hiring fairer, it optimizes for memorization and hiding. Candidates who excel in production often lean on tools. Your signal should reflect that reality.
AI-fluency framing
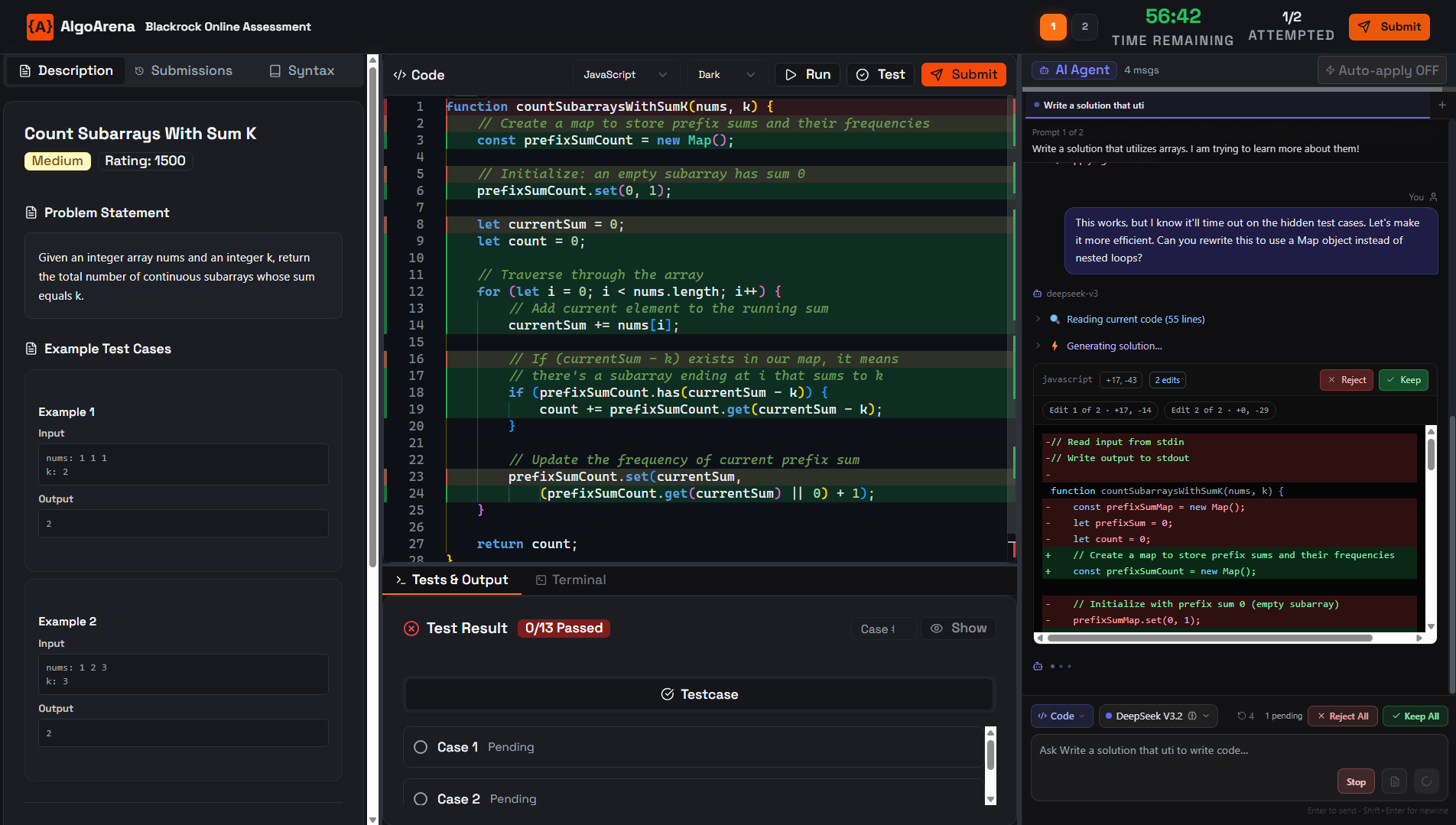
Strong engineers steer AI. They scope problems, write precise prompts, verify outputs, and iterate. AlgoArena captures those behaviors so you hire for how people ship, not how they perform without their stack.
In the reviewer view, open a candidate, scrub the timeline, and see prompts, tests, and decision notes.
- Keep it artifact-first. One clip should show timeline scrub, prompt view, and test results together.
- No cinematic pans, just a clean screen recording.
- End on a concrete decision action (Shortlist / Reject / Notes).
Once you record, we’ll swap `videoSrc` in and this block becomes a real product artifact.
Concrete signals we measure
Specificity, context, intent, not just volume.
Refinement vs blind retries, with depth per sub-goal.
Runs after AI edits, error recovery, test discipline.
Efficiency with quality, not speed alone.
Apply-without-verify is a risk signal.
Purposeful model use across plan / code / debug.
Watch them
work.
Go beyond the final score. Watch a full replay of how the candidate approached the problem. See every keystroke, when they tabbed out, and how quickly they recovered from compilation errors, rendered as a scrubbable timeline, not a wall of logs.
Embrace the
AI era.
Instead of banning AI and shipping spyware, we provide a built-in assistant and score how effectively the candidate collaborates with it. Blind copy-pasters are visible. Thoughtful prompters get credit for the skill they actually have.

Move beyond
LeetCode.
Spin up full-stack Next.js or Python environments in the browser and ask candidates to fix a bug in a multi-file architecture, or write a unit test suite from scratch. Assess the work, not the puzzle.

Competitive snapshot
They simulate a world that no longer exists, and we measure how candidates work in the one that does.
| Capability | Traditional OA | CoderPad | CodeSignal | AlgoArena |
|---|---|---|---|---|
| AI Fluency Score + dimensional radar | ✗ | ~ | ~ | ✓ |
| Multi-agent orchestration scoring | ✗ | ✗ | ✗ | ✓ |
| Session replay + AI lineage | ~ | ✓ | ~ | ✓ |
| Anti-gaming via behavior (not spyware theater) | ~ | ~ | ~ | ✓ |
| Code attribution (human / AI / hybrid) | ✗ | ✗ | ~ | ✓ |
Early access (OA in progress).
We’re building AI-native assessments that measure how candidates actually work. If you want a pilot when it’s ready, we’ll set it up with you.
Questions hiring teams ask
How is this different from CoderPad or CodeSignal?
Those tools assume AI is either blocked or irrelevant. We treat it as the actual production environment. Candidates can use AI in-assessment, and we score how effectively they do. See the competitive snapshot above for specifics.
What about anti-cheating?
We use behavior analysis (tab focus, paste attribution, iteration patterns) instead of webcam proctoring. Cheaters exhibit measurably different patterns. It's also more respectful to candidates, and nobody loves a hiring flow that installs spyware on their laptop.
How much does it cost at scale?
OA mode is still in development. When we open pilots, pricing will scale by candidate volume (not seats) because hiring is bursty.
Can I use my own problems?
Yes. You can pick from the curated library or upload your own multi-file workspace problems. Your content stays yours.
How do I actually get started?
Join early access, tell us what roles you’re hiring for, and we’ll set up a pilot as OA mode matures.
Hire with certainty.
Join early access and we’ll set up a pilot when OA mode is ready.
No card required to start.